Amazon Aurora 架构分析
Intro
Amazon Aurora is a relational database service for OLTP workloads offered as part of Amazon Web Services (AWS).
OLTP(On-line Transaction Processing) OLAP(On-Line Analytical Processing) 用户 操作人员,低层管理人员 决策人员,高级管理人员 功能 日常操作处理 分析决策 DB 设计 面向应用 面向主题 数据 当前的, 最新的细节的, 二维的分立的 历史的, 聚集的, 多维的集成的, 统一的 存取 读/写数十条记录 读上百万条记录 工作单位 简单的事务 复杂的查询 DB 大小 100MB-GB 100GB-TB
相关论文 Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases 发表在 SIGMOID 2017。

这是 Aurora 的总体架构。其中 RDS 指 Relational Database Service。Primary RW DB 是主数据库,读写请求都可以经过,也只有一个。Secondary RO DB 是只读数据库,只处理读请求,可以有多个。但这个架构最大的特点在于,数据并不在 RW DB 或 RO DB 手中,他们只负责接收请求,RW DB 负责产生 Log。Log 传递到 RO DB 作备份以及下面的六个存储节点。存储节点不仅存储数据,将 Log 实际应用到 data page 也由它们完成,意义在于减少网络传输。至于 S3 是一个备份快照的亚马逊服务 Amazon Simple Storage Service,看成更多一层备份就行。

在亚麻的 30 分钟测试内,Aurora 比传统 MySQL 完成了多 34 倍的事务,每个事务的 IO 减少到了 1/8。
Build History && Details
Easy Replica
首先为了让数据不是单份而是至少双份,亚麻搞了个 EBS (Elastic Block Store)。其实就是一对互为副本的存储服务器。它们之间采用 Chain Replication。
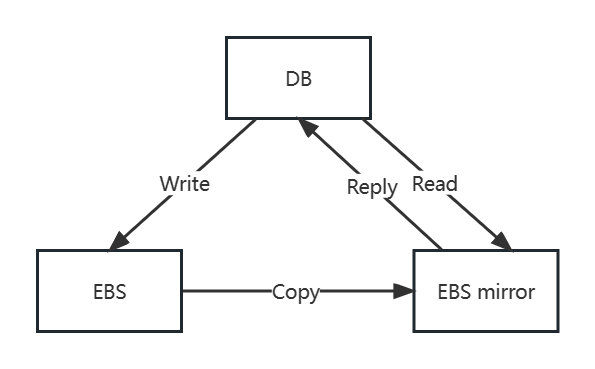
但是这还远远不够,首先如果你在 EBS 上简简单单跑一个 MySQL,那这个 Copy 的代价会很大(不仅要传输 Log ,还可能要传输 Data Page,具体原因我也不太清楚)。
另外,亚麻把一个 EBS(本体+mirror)跑在一个数据中心(论文称之为 AZ(Available Zone)),这样也很有道理,毕竟一个数据中心可以直接用高速网线相连,传输速度很快很稳定。但是如果这个数据中心炸了,那就两份一起没有了。
Backup in Different Area
为了让一个数据中心可以爆炸而不损失数据,所以我们需要把数据放到多个数据中心。
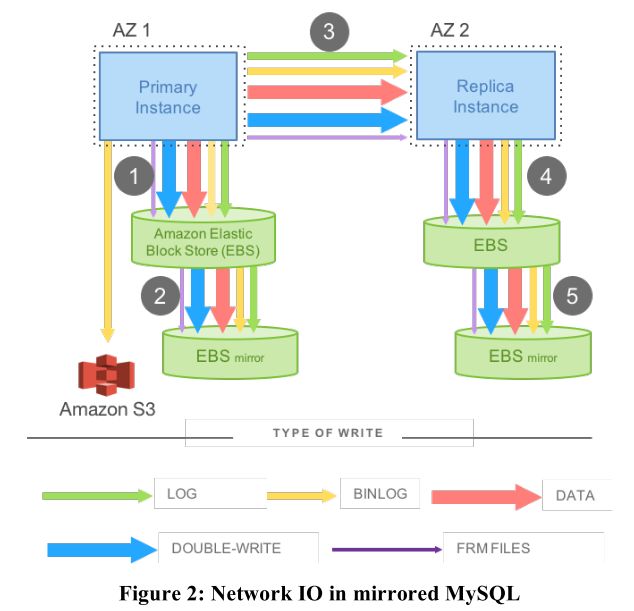
上述的 EBS 并没有被抛弃,而是每个数据中心跑一个 EBS 对。
其中,第1,3,5步是串行的,也就是说,只有第1步完成了,才能执行第3步,第3步完成了才能执行第5步。这无疑增加了服务器返回数据的延迟。另外传统的 MySQL 在写入和传输数据时还需要很多的额外信息,这又增加了网络带宽的消耗。也就是说,MySQL 的使用在分布式系统产生了两个问题:
- 应答延迟太高。
- 消耗网络带宽太多。
Only Log
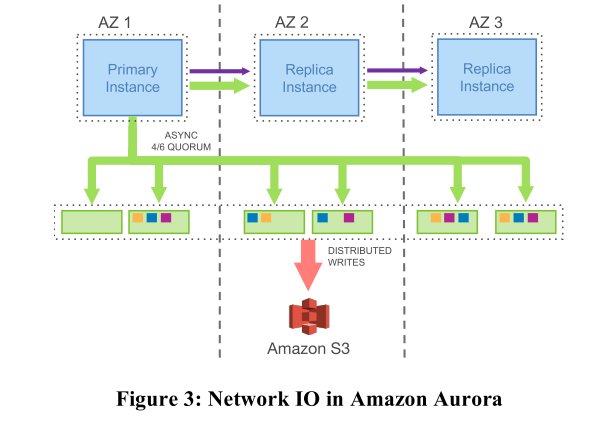
亚麻抛弃了 MySQL 和 EBS,从头到尾自己重新定制。每个数据中心放两个存储节点,但不是以 EBS 的形式组织。这里的存储节点不再是通用(General-Purpose)存储,这是一个可以理解MySQL Log 条目的存储系统。EBS 是一个非常通用的存储系统,它模拟了磁盘,只需要支持读写数据块。EBS 不理解除了数据块以外的其他任何事物。而这里的存储系统理解使用它的数据库的 Log。所以这里,Aurora 将通用的存储去掉了,取而代之的是一个应用定制的(Application-Specific)存储系统。
在一个故障恢复过程中,事务只能在之前所有的事务恢复了之后才能被恢复。所以,实际中,在 Aurora 确认一个事务之前,它必须等待 Write Quorum 确认之前所有已提交的事务,之后再确认当前的事务,最后才能回复给客户端。
这里的存储服务器接收 Log 条目,这是它们看到的写请求。它们并没有从数据库服务器获得到新的 data page,它们得到的只是用来描述 data page 更新的 Log 条目。
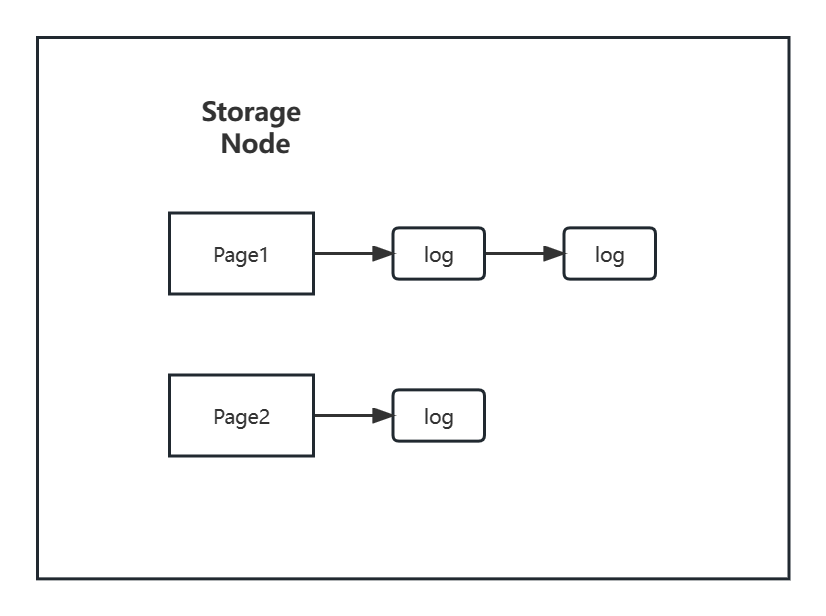
但是存储服务器内存最终存储的还是数据库服务器磁盘中的 page。在存储服务器的内存中,会有自身磁盘中page的 cache,例如 page1(P1),page2(P2),这些 page 其实就是数据库服务器对应磁盘的 page。
Log 交给了存储节点就算成功,就可以返回给 client 了,而不用等实际执行完到 data page,响应速度也大大提升。而读的时候,如果之前的 Log 还没执行完,那会赶紧执行一下更新 data page,让读等一等。也就是说存储节点的 cache 可能是这样的:
Quorum
然而,我们看到图中,一次写请求要告诉整整六个节点,比 Mirrored MySQL 那幅图还要多,虽然只需要传 Log 减少了网络传输,但万一六个节点里某个处理得比较慢/某个 AZ 离得太远,那也会带来高延迟的 Reply。
Quorum 简单理解这就是一个和 Raft 很像的机制,一个请求被正式承认不需要所有服务器都完成,而是达到一定数量就认为完成。这样可以大大减少一堆节点中比较慢的几个的影响。
假设有 N 个副本。为了能够执行写请求,必须要确保写操作被 W 个副本确认,W 小于 N。所以你需要将写请求发送到这 W 个副本。如果要执行读请求,那么至少需要从R个副本得到所读取的信息。这里的W对应的数字称为 Write Quorum,R 对应的数字称为 Read Quorum。
这里的关键点在于,W、R、N 之间的关联。Quorum 系统要求,任意你要发送写请求的 W 个服务器,必须与任意接收读请求的 R 个服务器有重叠。这意味着,R 加上 W 必须大于 N( 至少满足 R + W = N + 1 ),这样任意 W 个服务器至少与任意 R 个服务器有一个重合。这样做的意义在于,当我写入 W 个节点完成后,我读 R 个节点,一定至少读到一个已经被写更新的节点,这时我们就可以用版本号等手段,从读到的结果中选出最新的,也就获得了刚才写入的结果。
如果你不能与 Quorum 数量的服务器通信,不管是 Read Quorum 还是 Write Quorum,那么你只能不停的重试了。这是 Quorum 系统的规则,你只能不停的重试,直到服务器重新上线,或者重新联网。
为了实现 Aurora 的容错目标,也就是在一个 AZ 完全下线时仍然能写,在一个 AZ 加一个其他 AZ 的服务器下线时仍然能读,Aurora 的 Quorum 系统中,N=6,W=4,R=3。W 等于 4 意味着,当一个 AZ 彻底下线时,剩下 2 个AZ中的 4 个服务器仍然能完成写请求。R 等于 3 意味着,当一个 AZ 和一个其他 AZ 的服务器下线时,剩下的 3 个服务器仍然可以完成读请求。当 3 个服务器下线了,系统仍然支持读请求,仍然可以返回当前的状态,但是却不能支持写请求。所以,当 3 个服务器挂了,现在的 Quorum 系统有足够的服务器支持读请求,并据此重建更多的副本,但是在新的副本创建出来替代旧的副本之前,系统不能支持写请求。
Sharded Data / Protection Group
目前为止,我们已经知道 Aurora 将自己的数据分布在 6 个副本上,每一个副本都是一个计算机,上面挂了 1-2 块磁盘。但是如果只是这样的话,我们不能拥有一个数据大小大于单个机器磁盘空间的数据库。因为虽然我们有 6 台机器,但是并没有为我们提供 6 倍的存储空间,每个机器存储的都是相同的数据。如果我使用的是 SSD,我可以将数TB的数据存放于单台机器上,但是我不能将数百 TB 的数据存放于单台机器上。
为了能支持超过 10TB 数据的大型数据库。Amazon 的做法是将数据库的数据,分割存储到多组存储服务器上,每一组都是 6 个副本,分割出来的每一份数据是 10GB。所以,如果一个数据库需要 20GB 的数据,那么这个数据库会使用 2 个 PG(Protection Group),其中一半的 10GB 数据在一个 PG 中,包含了 6 个存储服务器作为副本,另一半的 10GB 数据存储在另一个 PG 中,这个 PG 可能包含了不同的 6 个存储服务器作为副本。
因为 Amazon 运行了大量的存储服务器,这些服务器一起被所有的 Aurora 用户所使用。两组 PG 可能使用相同的 6 个存储服务器,但是通常来说是完全不同的两组存储服务器。随着数据库变大,我们可以有更多的 Protection Group。
画个图看看,假设我们从亚麻那买了一个空间 30GB 的 Aurora 服务:

亚麻为 Aurora 服务起了很多 Storage Nodes 在各个不同的 AZ 数据中心(每个数据中心当然可以有多个 Storage Nodes,但我图里懒得画了)。我们可以把不同的 10GB 块放在不同的地方。读写不同的 10GB 块时,选取的六个节点也可以不一样。
Sharding 之后,Log 该如何处理就不是那么直观了。如果有多个 Protection Group,该如何分割 Log 呢?答案是,当 Aurora 需要发送一个 Log 条目时,它会查看 Log 所修改的数据,并找到存储了这个数据的 Protection Group,并把 Log 条目只发送给这个 Protection Group 对应的6个存储服务器。这意味着,每个 Protection Group 只存储了部分 data page 和所有与这些 data page 关联的 Log 条目。所以每个 Protection Group 存储了所有 data page 的一个子集,以及这些 data page 相关的 Log 条目。当然,这里支持的是简单的 PUT/GET 操作,如果有复杂的复合操作,需要自行用基本的操作组合出来。
另外,当一个 Storage Node 挂了的时候,如果我们采用完整地复刻出它这样的策略,在数据分片的情况下会有不好的效果。因为 Aurora 里亚麻的一个存储节点是任意用户的 10GB 块混合共用的,也就是说基本不存在和它一模一样的 Storage Node,它需要的数据需要从一大堆其他的 Storage Node 中汇集而成,这样多到一的汇集复制过程速度还是比较缓慢的。
于是,我们并不企图完整地复刻这个节点。而是把每个 10GB 块随缘恢复到一个其他的 Storage Node,这样就不再是多到一的复制,而是多到多的复制,恢复的过程就变成了并行的。这就是 Aurora 使用的副本恢复策略,它意味着,如果一个服务器挂了,它可以并行的,快速的在数百台服务器上恢复。如果大量的服务器挂了,可能不能正常工作,但是如果只有一个服务器挂了,Aurora 可以非常快的重新生成副本。
Read Only Node
Figure 3 有一些迷惑性,其实 Replica Instance 未必和下面的 Storage Nodes 存在 AZ 上的关联性,也未必只有 2 个。这些 Replica Instance 起到两个作用,一是当 Primary Instance 挂了的时候,选出一个顶上去;二是作为只读节点从 Storage Nodes 中读取数据,毕竟 Quorum 也是有代价的,连接也是有代价的,多分给几个机器总是好的。
为什么能写入的节点只有一个呢?因为要让 Log 以及其编号保持有序,这在多机上反而因要达成奇奇怪怪的共识而变得复杂,而单节点负责写就很容易。另外,读请求天然地比写要多,常常达到 100:1 的比例。
虽然 Replica Instance 作为 RO Node,只负责从 Storage Nodes 中读取数据,但 Primary Instance 还是要把 Log 传给他们(以 Chain Replication 的形式),这也许是因为 RO Node 需要 Log 来辅助判断缓存的新旧,以及是否处于事务中间等等问题,不要返回错误的读结果。
References
Lecture 10 - Cloud Replicated DB, Aurora - MIT6.824 (gitbook.io)