Chain Replication 与 CRAQ
Chain Replication

把一堆 server replica 排成一个链,当收到写请求时,传给 HEAD,HEAD 应用后通知下一个 replica 来应用,依次传递,直到 TAIL 应用后,回复给 client。读请求一律直接发给 TAIL。酱紫一来,客户能读到的都是已经存在于所有副本的数据。
在故障以及恢复方面,令人快乐的是它完全没有 Raft 那么多神秘的千奇百怪的情况,基本上就是一次 update 传到中途断了。
如果 HEAD 出现故障,作为最接近的服务器,下一个节点可以接手成为新的 HEAD,并不需要做任何其他的操作。对于还在处理中的请求,可以分为两种情况:
- 对于任何已经发送到了第二个节点的写请求,不会因为 HEAD 故障而停止转发,它会持续转发直到 commit。
- 如果写请求发送到 HEAD,在 HEAD 转发这个写请求之前 HEAD 就故障了,那么这个写请求必然没有 commit,也必然没有人知道这个写请求,我们也必然没有向发送这个写请求的客户端确认这个请求,因为写请求必然没能送到 TAIL。所以,对于只送到了 HEAD,并且在 HEAD 将其转发前 HEAD 就故障了的写请求,我们不必做任何事情。或许客户端会重发这个写请求,但是这并不是我们需要担心的问题。
如果 TAIL 出现故障,处理流程也非常相似,TAIL 的前一个节点可以接手成为新的 TAIL。所有 TAIL 知道的信息,TAIL 的前一个节点必然都知道,因为 TAIL 的所有信息都是其前一个节点告知的。
中间节点出现故障会稍微复杂一点,但是基本上来说,需要做的就是将故障节点从链中移除。或许有一些写请求被故障节点接收了,但是还没有被故障节点之后的节点接收,所以,当我们将其从链中移除时,故障节点的前一个节点或许需要重发最近的一些写请求给它的新后继节点。这是恢复中间节点流程的简单版本。
CRAQ
Chain Replication with Apporation Query,也就是能够分散处理读请求的 CR。
直接参考一下:
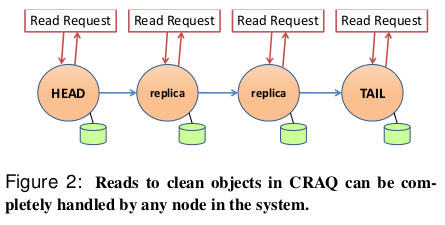
CRAQ 是链式复制的一种改进,它允许链中的任何节点执行读操作:
- CRAQ 每个节点可以存储一个对象的多个版本,每个版本都包含一个单调递增的版本号和一个附加属性( 标识
clean还是dirty)- 当节点接收到对象的新版本时(通过沿向下传播的写操作),该节点将此最新版本附加到该对象的列表中
- 如果节点不是尾节点,则将版本标记为
dirty,并向后续节点传递写操作- 如果节点是尾节点,则将版本标记为
clean,此时写操作是已提交的。然后,尾节点在链中往回发送ACK来通知其他节点提交- 当对象版本的
ACK到达节点时,该节点会将对象版本标记为clean。然后,该节点可以删除该对象的所有先前版本- 当节点收到对象的读请求时:
- 如果请求的对象的最新已知版本是干净的,则节点将返回此值
- 否则,节点将与尾节点联系,询问尾节点上该对象的最后提交版本号,然后,节点返回该对象的此版本
对于读操作, CRAQ 支持三种一致性模型,是可以通过不同手段选择实现的:
- 强一致性:最基本的读操作可以使每次读取都读到最新写入的数据,因此提供了强一致性。
- 最终一致性:允许节点返回未提交的新数据,即允许 client 可从不同的节点读到不一致的对象版本。但是对于一个 client 来说,由于它与节点建立会话,所以它的读操作是保证单调一致性的。
- 带有最大不一致边界的最终一致性:允许节点返回未提交的新数据,但是有不一致性的限制,这个限制可以基于版本,也可以基于时间。如允许返回一段时间内新写入但未提交的数据。

Comparing to Raft
Throughput

Raft 因为由单一 Leader 来处理所有读写,并且通知所有其他 replica,当 replica 数量多了的时候,Leader 承担了过大的压力。

再看一遍 CR,这玩意儿把读和写某种意义上分开处理,所以一定程度上分担了压力。另外,HEAD 只负责通知下一个,于是也没有 Raft 那样的压力。
但也绝非没有弊病,一个一个向下传,但凡出现了某一个 replica 应用得比较慢,就会拖累整个链。而 raft 只要求过半就算成功,就没有这种问题。
Fail Recover
显然 Chain Replication 面临的错误情况更少,更加简单。
Brain Split
遗憾的是,简单的 CRAQ 无法避免/监测脑裂。如果链的中间网络断了,但其实各个 server 都还健在,那就会被恢复成两条独立的链,都认为自己是对的。至于到时候请求会到哪去就无从可知了,取决于进一步的实现细节。
Raft 是可以避免脑裂的,因为要收集过半的回应,不到一半是不会生效的。
More Realistic Usage
Chain Replication 并不能抵御网络分区,也不能抵御脑裂。在实际场景中,这意味它不能单独使用。Chain Replication 是一个有用的方案,但是它不是一个完整的复制方案。它在很多场景都有使用,但是会以一种特殊的方式来使用。总是会有一个外部的权威(External Authority)来决定谁是活的,谁挂了,并确保所有参与者都认可由哪些节点组成一条链,这样在链的组成上就不会有分歧。这个外部的权威通常称为 Configuration Manager。
Configuration Manager 的工作就是监测节点存活性,一旦 Configuration Manager 认为一个节点挂了(这其实是一个挺麻烦的问题,比如两个 server 间的网线断了,但他们和 Configuration Manager 都还能通信,那这要怎么算,怎么判定呢?),它会生成并送出一个新的配置,在这个新的配置中,描述了链的新的定义,包含了链中所有的节点,HEAD 和 TAIL。Configuration Manager 认为挂了的节点,或许真的挂了也或许没有,但是我们并不关心。因为所有节点都会遵从新的配置内容,所以现在不存在分歧了。
现在只有一个角色(Configuration Manager)在做决定,它不可能否认自己,所以可以解决脑裂的问题。
当然,你是如何使得一个服务是容错的,不否认自己,同时当有网络分区时不会出现脑裂呢?答案是,Configuration Manager 通常会基于 Raft 或者 Paxos。在 CRAQ 的场景下,它会基于 Zookeeper。而 Zookeeper 本身又是基于类似 Raft 的方案。

一个 Configuration Manager 可能管理多个数据系统,比如管理着一个分片的数据库,每个片的数据由一个 Chain Replication 系统来维护。Configuration Manager 可能管理着每个链的 HEAD 和 TAIL,也管理着分片的边界线等等。并且实际上,每个分片内也未必需要用 Chain Replication,Raft、Paxos 等等都可以作为选择。
References
9.5 链复制(Chain Replication) - MIT6.824 (gitbook.io)
9.6 链复制的故障恢复(Fail Recover) - MIT6.824 (gitbook.io)
9.7 链复制的配置管理器(Configuration Manager) - MIT6.824 (gitbook.io)