MIT-6.824 Raft
Part 2A - Leader Election
Visualization
Main Idea
RaftState
首先为了方便整体上锁,这里有参考一份网上的代码,将 raft 与 log 关系不大的几个关键 state 独立成 RaftState 这个结构体。
1 | const candidateState int = 0 |
deadlock 引用自:
1 | import ( |
它没啥特别的,就是重新包装了一遍 go 的 sync 里的锁,并添加了 online 的死锁检测。当它发现加锁顺序不对而有可能引发死锁/已经引发死锁时,会告诉你哪里和哪里的锁不太对劲,引发死锁。
通过一通整体的上锁,可以保证关键的 state 不要因为并发读写而发生混乱:
1 | func (rs *RaftState) rLock() { |
Initialization
1 | // init |
初始 term 为 0,初始未投票,以 -1 标记,初始为 follower。
mainLoop
原来的代码里统一给了个 ticker(),但是在这里面每隔一个 time unit 进行一些判断和处理,让三种状态(follwer、candidate、leader)的处理变得非常混乱,所以我们迫切需要将其分开(同样参考了网络上的思路),在 Make 中初始化后:
1 | // go rf.ticker() |
函数主体:
1 | func (rf *Raft) mainLoop() { |
由此,我们实现了三个不同 state 的处理解耦。
followerMain
1 | // 以 10 ms 为一个时间单位,没必要每 1 ms 判断一次 |
非常简单,如果收到了 reset timer 的信号,那么就 reset 时间,否则 timeout 开始选举。
什么时候 reset timer 呢?

收到 AppendEntries 或 grant vote 给别人时,设置 reset timer 的标记 rf.raftState.resetElectionTimer 为 true。
doElection / candidate
1 | func (rf *Raft) doElection() { |
这里就没啥 reset timer 了,同样每个 loopTimeUnit 检查一次,如果不是 candidate 了就退出。
不是 candidate 可能有这些原因:
- 收获过半投票,成为 leader。
- 被别人更新 term,成为 follower。
- 收到新 leader 的 AppendEntries,成为 follower。

如果超时了,自动进入下一轮 mainLoop,如果还是 candidate,自然会开启下一轮 doElection。
leaderMain
1 | func (rf *Raft) leaderMain() { |
前面初始化部分省略,每隔 40 ms 发一次心跳包。若已经不是 leader 则退出。
Async Message
因为很多地方都是要异步发送消息(至少比如群发心跳时,不可能一个个发,肯定每个都是 go 出去,不能等待上一个返回再发下一个,时间差太久了),所以我们需要设计一套异步方案。
以发送心跳包为例,其余均类似:
1 | func (rf *Raft) sendHeartbeatToAll() { |
大致可以看出,前半部分在异步地发送出心跳,后半部分在处理这些心跳的 reply。
先做了个 replyChannel,让请求异步发出去时,那个线程等待它返回并把结果传进这个 ch,然后下面循环处理的 part 就会收到,开始进行一次处理。
1 | func (rf *Raft) sendAppendEntriesWithChannelReply(to int, args *AppendEntriesArgs, reply *AppendEntriesReply, replyChannel chan WrappedAppendEntriesReply) { |
心跳这里我并没有做无限重发,因为反正 40 ms 后就会有新的了,没有必要。
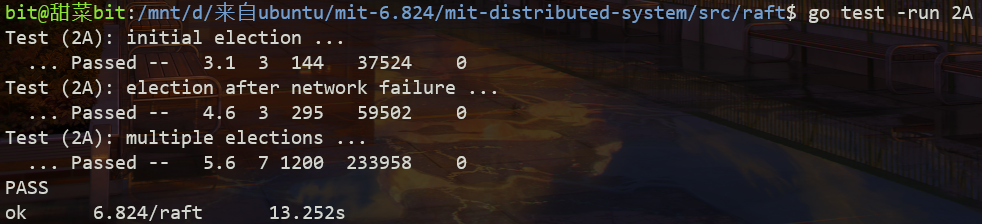
Results
Part 2B - Log Replication
Visualization
Main Idea
Running Log For Debugging
这里也参考了一个技巧,为不同 part 的 log 进行开关区分(electionDebug bool and logReplicationDebug bool )。
利用不同的包装 log 函数,我们可以自由选择想看到的 log part。
1 | func (rf *Raft) electionLog(format string, vars ...interface{}) { |
Definition & Initialization
1 | type Raft struct { |

1 | // log[0] is unused, just to start at 1. |
这里要关注的就是 log’s first index is 1。这么做是因为首先我们知道一开始没有日志被提交,而我们很多变量如 commitIndex、lastApplied 都需要一个初始值,以及 leader 发送的 RPC 中也有 prevLogIndex 这种参数。如果我们使用 index 为 -1 作为初始值,那么难以避免地需要在很多地方加上 if 的 -1 检查,避免出现非法数组 index,这造成了很恶心的麻烦。于是乎,我们用一个没用的 log[0] 开头,这样所有这些 index 都可以初始化为 0。
leaderInitDone
leaderInitDone 用于标记 leadaer 已经初始化完毕(如 nextIndex、matchIndex需要在成为 leader 时进行初始化),避免 leader 还未初始化完毕时开始处理 client 发送的 command,出现问题。
1 | func (rf *Raft) leaderMain() { |
在 Start ,也就是 client 发送给 leader 处理新 command 时,若 leaderInitDone 为 false,则等待 1 ms 后重新检查,直到 leaderInitDone。
1 | func (rf *Raft) Start(command interface{}) (int, int, bool) { |
中途出现过 leaderInitDone 一直是 false,sleep 根本停不下来。经过漫长的排查,发现是在 election 中成为 leader 后,直接被安排了 Start,压根还没进 leaderMain 进行 Init,所以我们需要在 Start 的等待过程中把锁释放,让 leader 有机会进行 init。而且又要注意,因为释放了锁,所以等待过程中 leader 的 state 也有可能被改变,需要在重新锁上时进行判断。
guarantee AppendEntriesArgs Term precise
因为 Start 后,AppendEntries 这种请求是异步地发出去的,所以是以一个 go 出去的形式,期间不能保证 raftState 一直上锁。如果在发送时已经被更新为了新的 term 以及 follower,那么就会表现为此 server 作为新的 term 的 leader 广播这条 command,这是不合理的。它应该用自己作为 leader 的 term 来广播这条 command,于是我通过提前获得 term,将锁住的 term 作为参数传入 sendAppendEntriesToAll,保证了 term 的正确性。
1 | go rf.sendAppendEntriesToAll(rf.raftState.currentTerm) |
Update commitIndex & apply
All Servers:
- If commitIndex > lastApplied: increment lastApplied, apply log[lastApplied] to state machine.
raft-extended 有这么一条。所以我们需要有这么一件事:在 commitIndex 发生改变时,进行一次 apply 的尝试。
我的实现是,每次 commitIndex 改变,给 applyNotifyCh 发送一个消息,另外搞一个 applyLoop 循环从 applyNotifyCh 获取消息,每当获取到,进行一次 apply 的尝试。若 apply 成功,将 applyMsg 发送进 applyCh(这个由调用 raft 的客户端提供)。
1 | func (rf *Raft) applyLoop() { |
When retry? When stop retry?
这个问题其实我并不是特别确定,但是目前的实现还是比较稳定的。
首先,所有的异步接收 reply 的循环对成功进行计数,全部成功后结束循环:
1 | successCount := 0 |
对于心跳包(Entries == nil),不重试,反正马上会有新的。
对于 AppendEntries (Entries != nil),term 更新了 / 不是 leader 了,结束。
1 | rf.raftState.rLock() |
对于 leader 的 AppendEntries 来说:
If last log index ≥ nextIndex for a follower: send AppendEntries RPC with log entries starting at nextIndex
If successful: update nextIndex and matchIndex for follower (§5.3)
If AppendEntries fails because of log inconsistency: decrement nextIndex and retry (§5.3)
注意,只有 log inconsistency 才 retry,因为 term 不对而直接 return false 的,不 retry。
重试时,更新 nextIndex,将 prevLogIndex 更新为 nextIndex - 1。另外,重试时,我们怎么知道这个请求是给哪个 server 的呢?所以,我们需要对 reply 进行一个包装,在异步发送的时候同时记录发送的信息,方便接收 reply 后处理并发给同一个 server。
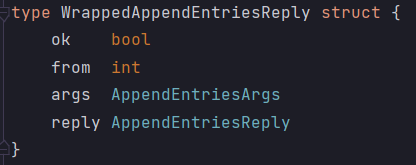
1 | func (rf *Raft) sendAppendEntriesWithChannelReply(to int, args *AppendEntriesArgs, reply *AppendEntriesReply, replyChannel chan WrappedAppendEntriesReply) { |
Whose log is newer?
Raft 采用投票的方式来保证一个 candidate 只有拥有之前所有任期中已经提交的日志条目之后,才有可能赢得选举。一个 candidate 如果想要被选为 leader,那它就必须跟集群中超过半数的节点进行通信,这就意味这些节点中至少一个包含了所有已经提交的日志条目。如果 candidate 的日志至少跟过半的服务器节点一样新,那么它就一定包含了所有以及提交的日志条目,一旦有投票者自己的日志比 candidate 的还新,那么这个投票者就会拒绝该投票,该 candidate 也就不会赢得选举。对应 RequestVote RPC 中的这个:

怎么判断谁的日志更新?
单纯的看Term可以么?其实是不可以的,因为一个节点可以不断增加自己的Term,那么一个节点的Term更高并不意味着其日志更新。我们需要比较的是节点的最后一个日志是在什么Term产生的。
因此,采用下面的判定方法来判断两个节点 N1 和 N2 的日志新旧程度。
- 如果N1 的最后一条日志的 Term >N2 的最后一条日志的Term,那么 N1 的日志更新;如果二者 Term 相等,则进入下一步;否则 N2 的日志更新。
- 在一个 Term 中往往会有很多条日志,而这些日志则会被分配一个序号也就是 index。那么如果 N1 的最后一条日志的 index >N2 的最后一条日志的 index,那么 N1 的日志更新;如果二者 index 相等,则一样新;否则 N2 的日志更新。
如果 N1 的Term > N2 的Term,那么 N1 的日志更新;如果二者 Term 相等,那么二者日志同样新;否则 N2 的日志更新。这条没必要考虑,因为在 RequestVote 中,如果 term < currentTerm,直接返回 false 了。
这里判断的时候我们可以回顾之前的日志匹配特性(Log Matching Property):
Raft 会一直维护着以下的特性,这些特性也同时构成了图 3 中的日志匹配特性(Log Matching Property):
- 如果不同日志中的两个条目有着相同的索引和任期值,那么它们就存储着相同的命令
- 如果不同日志中的两个条目有着相同的索引和任期值,那么他们之前的所有日志条目也都相同
第一条特性源于这样一个事实,在给定的一个任期值和给定的一个日志索引中,一个 leader 最多创建一个日志条目,而且日志条目永远不会改变它们在日志中的位置。
第二条特性是由 AppendEntries RPC 执行的一个简单的一致性检查所保证的。当 leader 发送一个 AppendEntries RPC 的时候,leader 会将前一个日志条目的索引位置
PrevLogIndex和任期号PrevLogTerm包含在里面(紧邻最新的日志条目)。如果一个 follower 在它的日志中找不到包含相同索引位置和任期号的条目,那么它就会拒绝该新的日志条目。一致性检查就像一个归纳步骤:一开始空的日志状态肯定是满足日志匹配特性(Log Matching Property)的,然后一致性检查保证了日志扩展时的日志匹配特性。因此,当 AppendEntries RPC 返回成功时,leader 就知道 follower 的日志一定和自己相同(从第一个日志条目到最新条目)。
Raft算法 - 知乎 (zhihu.com) 这里面有一些奇妙问题的详细解说。
Results
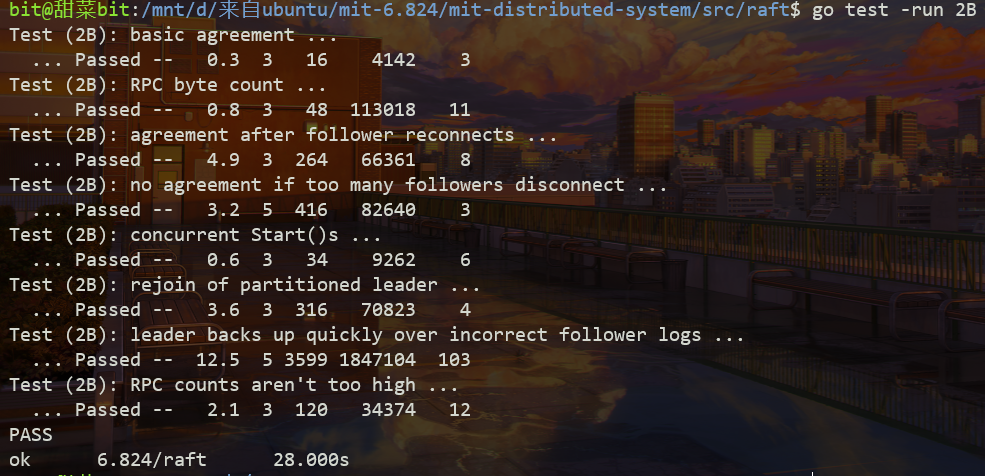
Part 2C - Persistence
这个 part 其实自己的代码非常简单,但是测试用例非常的强,导致会发现不少前面的 part 的问题。
Main Idea
Serialization
1 | // 内部不锁,外部来锁 |
注意这里加装了一个 len(rf.log),为后续反序列化提供便利。
Deserialization
1 | // |
When to persist

我做得非常简单:每次这些量改了就 persist。
Figure8Unreliable2C
著名的一个难过的点,具体就是前期因为网络被设置为 unreliable 并且经常搞点 connect disconnect 的小动作,导致会有一大堆 Log 冲突(几百条),后期一个个地 retry 根本来不及,很快就超时了。
然后发现这一点已经给了 hint:

文章的提示是这样的,可以在发现不同时,一次性直接退到本地的冲突 log 所在 term 的第一条 log (因为这个 term 内的 log 可能都是自己自嗨生成的)。
于是这样修改,在 AppendEntriesReply 中增加一项下次 retry 的 nextIndex,来加快重试的速度。
1 | if args.PrevLogIndex > len(rf.log)-1 || (args.PrevLogIndex >= 0 && rf.log[args.PrevLogIndex].Term != args.PrevLogTerm) { |
于是顺利通过。
另外需要注意的是,只在 log inconsistent 的时候进行重试,而不会在 leader 的 term 过老时重试。这一点需要 leader 接收 reply 时判断清楚。
Results
Part 2D - Log Compaction
理清思路和难点参考了:MIT6.824-lab2D-2022(日志压缩详细讲解)_幸平xp的博客-CSDN博客
Hint
What the Copy on Write when creating snapshots means?
当创建一个 Snapshot 并序列化的时候,我们可能需要很长的时间,如果这期间就这么阻塞了,会带来比较大的影响。
Copy on Write 指借用 Linux 的 fork,直接先上锁暂停,fork 一个一模一样的子进程(还没有自己的空间,指针指向父进程的空间),当父进程/子进程中的任何一方想要发生变更时,子进程对父进程的空间进行一次完全一样的拷贝,变成自己的私有空间,然后进行创建 Snapshot 的操作。这样一来,创建 Snapshot 的暂停时间从完完全全创建和序列化 Snapshot,变成了一次进程拷贝的时间,大大减少了时延。
我感觉,简单做就是:首先锁住,整个 log 拷贝;然后解锁,在一个新线程中做创建 Snapshot 这件事即可。
参考了:深入Raft中的日志压缩 - 知乎 (zhihu.com)
然鹅,实际上这个 lab 里并不需要关注这一点。
How functions of 2D would be used?
func (rf *Raft) Snapshot(index int, snapshot []byte)在 `persister.go` 中,有 ReadSnapshot 函数。Service 层以此来在崩坏重启后,读取快照。1
2
3
4
5
6
7
8
9
10
11
由 Service 层来调用 rf.Snapshot,让该 server 用快照来替换前面的日志。index 为快照包含的最新 Log index,snapshot 为 service 层(如 kvraft)快照的字节流。
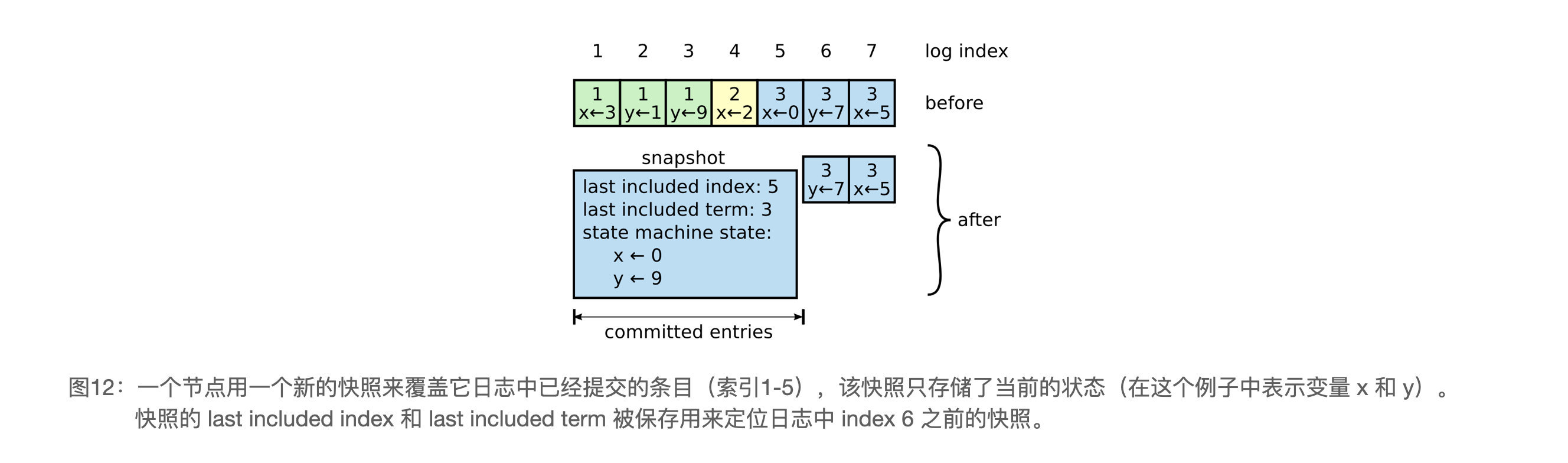
> 这个图的意思并不是 snapshot 里包含 lastIncludedTerm 和 lastIncludedIndex,只是 raft 应该保存并持久化他们俩。snapshot 里只包含 service 层的数据。
另外,Snapshot 只用于 ***server 上传一些 log 后,被通知一部分 log 已经生成快照,Service 指示 server 进行日志压缩***。从 crash 状态的恢复并不走这个函数。
+ ```go
func (ps *Persister) ReadSnapshot() []byte```go
func (ps *Persister) SaveStateAndSnapshot(state []byte, snapshot []byte)1
2
3
4
5
6
7
8
9
10
11
raft server 自己将 raft 的 state 处理成字节流后和 snapshot 一起存进持久化存储。
+ 
当某个 follower 过于落后时,Leader 调用 follower 的这个 RPC,让它用快照迅速更新。
注意,论文中这里的 Snapshot 的 data 使用了 offset 和分块传输的方法,但是本实验为了简单起见,这是不要求实现的,只需要一整个 snapshot 进行传输即可。
+ ```go
func (rf *Raft) CondInstallSnapshot(lastIncludedTerm int, lastIncludedIndex int, snapshot []byte) bool因为 applyCh 现在既要处理正常的日志追加,又要让快照也走这个 ch,所以有可能发生混乱(具体还没想清楚),但是据说只要管理好同步问题,这个函数现在是没有必要的,可以保持返回 true 就行。
Save lastIncludedIndex and lastIncludedTerm
快照中包含的最后一项 log 的信息应当被保存为 raft 的 state,并且也由 persister 进行持久化。
Main Idea
Log Index Wrapping
这里面的一大问题是,在经过了 Snapshot 后,日志只剩下后面的部分,所以原来的代码里需要做全面的下标(index)更换。以及,我们需要为 Raft 增加两个状态:lastIncludedIndex,lastIncludedTerm,来记录 Snapshot 到哪里了。因为这两个实际上是日志的部分,所以和 log 共用 logMutex,并且需要一起持久化哟~
还有一点,我们依然要保持 log[0] 是没什么屁用的,所以 lastIncludedIndex 这一条可以保留下来当 log[0] ,实际有效的从 log[1] 开始。
1 | // need to lock logMutex outside by caller, return max valid log index + 1 |
Prevent from Index Overflow
因为很多 log 被包含进了 Snapshot 里,所以一旦要读取更早的日志,可能就要 InstallSnapshot 了,这很浪费时间,我们需要避免没必要的 Index Overflow。
首先,在我写的过程中发现了 lastIncludedIndex 和 nextIndex、matchIndex 等数据发生倒退的情况,这些数据都是不应该倒退的,倒退了很有可能就访问 snapshot 里的日志了。发生倒退的原因基本上是因为并发高了,反应不过来,导致时序错乱,小的覆盖大的。为他们加上保护措施,只有增加才修改数值。
When Own lastIncludedIndex is larger than PrevLogIndex
有些运气差的时候,发现 leader 发来的 PrevLogIndex 比本 follower 的快照 index 还要小。但在别的 bug (特别是 nextIndex 相关的)修完后,这件事情好像不复存在了,因为 leader 一定拥有所有已经 applied 的日志,所以 PrevLogIndex 不会比其他 follower 的快照 index 小。
加了个小处理,现在看来可能是无用功:
1 | if rf.lastIncludedIndex > args.PrevLogIndex { |
Never Go Backward
在 InstallSnapshot 中,我们也需要注意,如果发来的快照比手头已经提交的日志 rf.lastApplied 还要旧(这在并发度比较高的时候完全可能发生),那显然是不要执行 install 的。在安装了 leader 发来的快照后,显然我们也需要更新一下 lastIncludedIndex,lastIncludedTerm,lastApplied,commitIndex 等等。
Share applyCh with Common logs
我们同样使用 applyCh 来把快照数据传给状态机。结构体中区分了快照和普通的日志:
1 | type ApplyMsg struct { |
Keep consistent without waiting for next log
在发现某个 follower 落后太多,发给他 snapshot 后,任务还没结束,还需要继续让那个 follower 更新到最新的 log 才行。于是在 sendSnapshot 中递归地发送更新,如果 send 完 snapshot 后又太落后了,那就继续发新的 snapshot,如果进度就差一些,那把后缀的几个 log 通过 sendAppendEntries 发过去。
Better the code structure
我原本写的结构是:在一个 sendAppendEntriesToAll 函数中,并发地调用各个 server 的 RPC 后,各个线程都把结果传回一个 channel,在 sendAppendEntriesToAll 中弄一个循环来读取这个 channel,依次处理返回值。然鹅,当出现了发送快照这个不一样的需求后,channel 的参数类型又不得不进行进一步的包装,十分恶心。于是,还是把失败重试的处理和成功结果的处理也都放进了并发 go 出去调用 RPC 的线程中,这样也免除了在单一 channel 中分辨是哪个 server 的返回的麻烦。
1 | func (rf *Raft) sendAppendEntriesToAll(thisTerm int) { |
TIPS
Lock Order
rf.raftState -> rf.peerLogMutex -> rf.logMutex -> rf.commitMutex -> rf.leaderInitMutex
Some Pities
这个 lab 2 Raft 做到最后还是留下了遗憾:它并不是那么稳定地通过测试,而是会发生死锁——主要是在关闭打印日志的时候发生。在打开打印日志时,死锁便变得罕见了,看起来有些离奇。我在完成后阅读了其他人的实现,发现大部分稳定的代码都是用了框架本身提供的 mu 那唯一一把互斥锁,而不是像我一样使用非常复杂的四五把读写锁来完成整个流程。
我确信我的代码严格地按照 Lock Order 来进行五把锁的顺序上锁,然而死锁并没能被完全避免,并且有些时候看起来并不是彻底的死锁,而是发生了饥饿,我在 go-deadlock 的报错中看到了许多次这样的情况——锁的持有者完全不具备长期持有锁的可能。我了解到读写锁中,读锁的并发持有可能让写锁陷入饥饿。我也了解到当一个 golang 中的读写锁正被读锁,并有写锁在排队时,其他的读锁无法继续加上去等等。在 6.824 前,我对 golang 一无所知。
如果来日对读写锁以及死锁避免有了更多的理解,也许会回来再思考思考。
时隔一个月,我在看到一篇文章描述了略有类似的问题后,突然发觉了我的错误,真是不可思议)。
我是用一个
tryIncrementCommitIndex函数来让leader的 commitIndex 增加的,因为 leader 需要在检查到所有 follower 都收到了一条 log 后,才 commit 它。我原先的处理是,每次收到 AppendEntires 的 RPC reply 时,如果发现某个 follower 更新了日志,那就 go 一个 tryIncrementCommitIndex。然后的情况就是,tryIncrementCommitIndex 总是会占用某把锁长达 30s 而触发 deadlock 监测。我也说了,我怎么也没找到死锁发生的可能。现在看来,是 tryIncrementCommitIndex 线程数太多,把整个锁资源挤爆了,导致其他线程的饥饿。
原因清楚了之后,解决起来就很简单:tryIncrementCommitIndex 太多了,那就干脆只启动一个线程,当 leader 初始化完毕后,
go rf.tryIncrementCommitIndex,保持循环,每次循环 sleep 一段时间(我最后设置成 20ms),再不断检测 commitIndex 是不是可以增加了。如果不是 leader 了,退出循环。新 leader 会启动这个函数。当 leader 的 commitIndex 增加后,通过心跳或真正的 AppendEntries,follower 们也会很快增加 commitIndex。中间还有一个小插曲,那就是 applyNotifyCh 也爆满了,导致阻塞),可能 tryIncrementCommitIndex 的节奏不太好把握。我索性把 applyNotifyCh 的 buffer 从 10 调到了 500,死锁的问题被彻底解决了。